SOCIEDAD
El milagro de la IA: este paciente de ELA volverá a escuchar sus pensamientos con su propia voz
El emocionante regreso de la voz propia para un paciente de ELA.
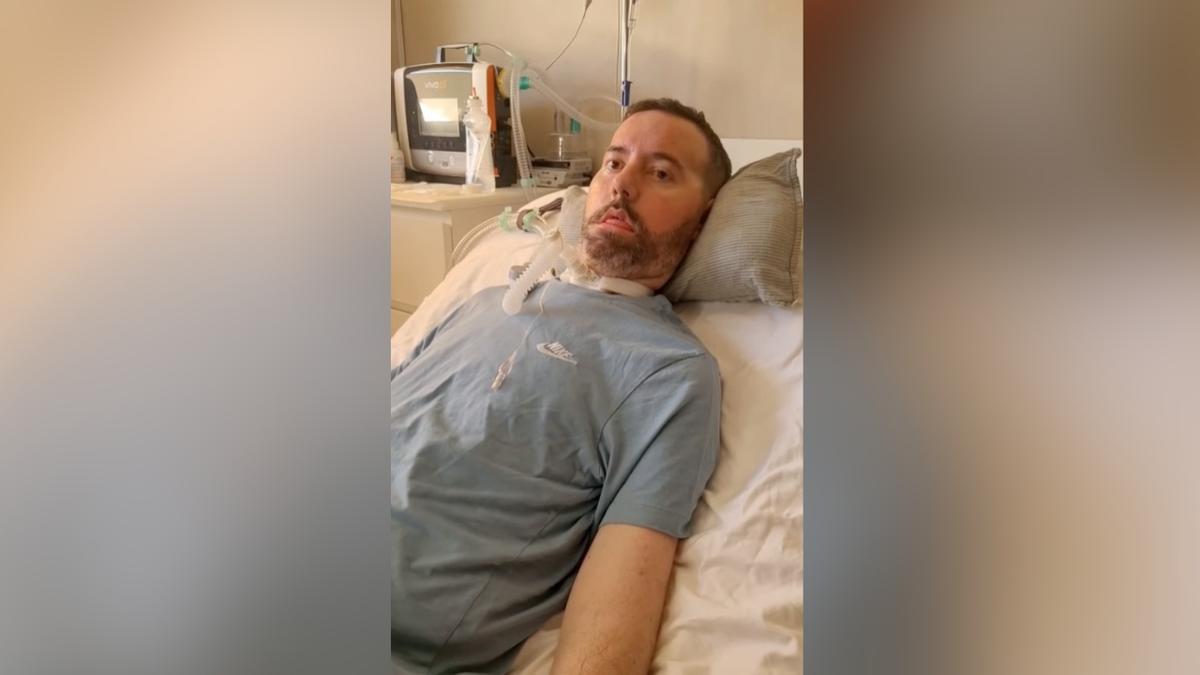
Fran Vivó

Fran Vivó, un exbombero forestal de 36 años y vecino de Benaguasil, afectado por Esclerosis Lateral Amiotrófica (ELA), vivirá un momento muy especial al poder volver a escuchar su propia voz tras años comunicándose exclusivamente mediante una tablet que transformaba en audio lo que escribía con sus ojos.
Hasta ahora, esa voz era un sonido robótico e impersonal, similar al que solemos recordar de Stephen Hawking. Ahora, gracias a la presencia de Fran en redes sociales, sabemos que volverá a esuchar su propia voz gracias a la Inteligencia Artificial.
La reconstrucción de su voz
Lo que marcará la diferencia esta vez es una reconstrucción fiel y emotiva de la voz que Fran tenía antes de la enfermedad y la traqueotomía, lograda mediante un avanzado sistema de inteligencia artificial que ha utilizado 20 minutos de grabaciones antiguas en WhatsApp de Fran, su familia y amigos.
Este modelo de voz no solo reproduce palabras, sino también matices, emociones e intenciones, recuperando el tono auténtico tanto en castellano como en valenciano.
Este avance ha sido desarrollado por el grupo de investigación VertexLit bajo la dirección de Jordi Linares, dentro del Instituto Universitario Valenciano de Investigación en Inteligencia Artificial (VRAIN) y la red ValgrAI. La presentación oficial tendrá lugar en la II Jornada de VRAIN en el campus de Alcoy de la Universitat Politècnica de València.
La recuperación de la voz de Fran Vivó representa un avance sin precedentes en el campo de la inteligencia artificial aplicada a la salud, especialmente para personas con enfermedades degenerativas como la ELA.
Gracias a la combinación de tecnología avanzada y muestras de audio personales, se ha logrado crear una réplica vocal con una naturalidad tal que transmite emociones y matices únicos, ofreciendo una experiencia mucho más humana que los sistemas tradicionales de síntesis de voz.
- ¿Cuánto cuesta la camisa que utilizó Pep Guardiola?
- Santiago Segura revela el drástico cambio físico detrás del personaje Torrente
- El surrealista sueño de Andreu Buenafuente con Laporta que desató risas en 'Nadie sabe nada'
- La Guardia Civil analiza una prenda íntima y un mechón de pelo que guardaban los asesinos de Francisca Cadenas
- La abogada de la familia de Francisca Cadenas: 'A día de hoy hay indicios de que pudo haber un móvil sexual
- Gonzalo Bernardos revela las ciudades donde comprar vivienda en 2026: 'Puedes conseguir un incremento en tu patrimonio
- Hacienda lo confirma: devolverá cerca de mil euros en la Renta 2026 a quienes cumplan este requisito
- Mustafa Suleyman, jefe de IA de Microsoft, pone fecha al fin del trabajo de oficina y advierte de que podría llegar antes de lo previsto